RM 분류 알고리즘 (1) - Default & k-NN
- sompak
- 2017년 3월 24일
- 2분 분량
RapidMiner에는 굉장히 많은 분류 알고리즘들이 기본적으로 내장 되어 있습니다. 모든 알고리즘을 설명하기는 힘들겠지만 하나하나 포스팅 해보려 합니다. ^^;
이번 포스팅에는 Default Model 과 k-NN (k-Nearest Neighbor)에 대해서 이야기 해보려 합니다. 이 두 개의 알고리즘은 RapidMiner에서 Lazy라는 폴더 안에 들어 있습니다. 이 두 개의 알고리즘은 우리가 흔히 이야기하는 학습이라는 개념이 거의
들어 있지 않기에 게으른 알고리즘 이라 불리우고 있습니다.
(특히 k-NN)
1. Default Model
이 Operator는 알고리즘이다 라고 하기에 부끄러울 정도의 기능을 가지고 있습니다.
분석 데이터에서 오직 타겟(Label) 칼럼에만 관심을 갖기 때문입니다. 다시 말해 타겟 칼럼의 데이터가 Yes 60, No 40 이라면 새로운 데이터에 대한 예측값은 무조건 Yes 입니다. 학습 데이터에서 Yes가 많았기 때문에... 만약 타겟 칼럼이 수치형 데이터라 한다면 새로운 데이터의 예측값들은 전부 학습데이터 타겟 칼럼의 평균 혹은 중간값을 가질 것 입니다.
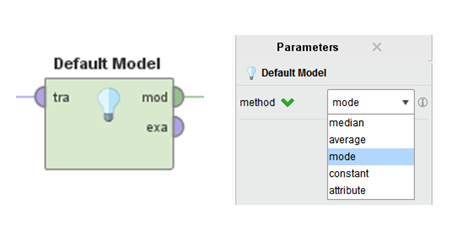
우리의 선택이 필요한 것은 (Parameter) 타겟 칼럼의 데이터 타입에 맞는 계산 방법 밖에는
없습니다. 어찌 보면 Default Model은 가장 사람의 직관적인 판단과 유사할 것 같습니다.
과정 보다는 결과에 대한 기억을 가지고 지금도 누군가를 혹은 무엇을 판단하고 있지 않으신가요? :)
2. k-NN (k-Nearest Neighbor)

최근접 이웃이라고 불리우는 알고리즘으로 데이터를 학습용이 아닌 검색용으로 사용하는 방법입니다. 다시 말해 새로운 데이터에 대해서 해당 데이터와 동일한 혹은 비슷한 데이터를 찾아 내어 그 데이터들이 가지고 있는 타겟 데이터를 예측 값으로 하는 방법입니다. 새로운 데이터의 주변 이웃 데이터들이 Yes 60%, No 40%라면 다수결 원칙에 따라 Yes 값이 되고, 만약 수치형 타겟 이라 한다면 주변 데이터들의 값들의 평균 값이 예측 값이 될 것 입니다.

그렇다면 k-NN을 위해 우리가 고민해야 할 것들은
1) 과연 몇 개의 이웃 데이터들의 데이터를 참고 할 것인가?
> 가장 중요한 판단 요소로서 정답은 없습니다. 계속 k값을 변경하여 모델의 성능을 비교해야 할 것 입니다. 다만 타겟이 이산형이라 한다면 k는 홀수로 설정하는 것이 좋습니다.
2) 이웃이라고 판단 하는 근거를 무엇으로 할 것 인가?
> 데이터 간의 거리 또는 유사성을 통해 판단하고 있습니다. 하지만 데이터간의 거리 및 유사성에 대한 방법은 너무나도 많아 또 하나의 거대한 학문입니다. ㅜㅜ 그래서 RapidMiner에서
추천하는 MixedMeasures방법을 이용하고 그것을 기준으로 다른 척도를 선택하여 성능을
시험해서 판단하는 것이 좋을 것 같습니다.
3) 이웃들에 대한 레벨을 줄 것인가?
> 이웃이 여럿일 때 더 가까운 이웃들의 의견에 좀 더 많은 가중을 줌으로서 레벨을 나눌 수 있을 것입니다. Weighted Vote에 체크 되면 가중을 주게 되고 가중치에 대한 방법은 RM에 설정된 방법으로 진행 됩니다.
RapidMiner에서는 각각의 파라미터들을 자동으로 변경하며 모델의 성능을 비교하여 가장 최적 값을 찾아 주는 Optimization Operator가 있습니다. 이를 통해 최소한의 노력으로 최적의 값을 찾을 수
있을 것 입니다.









